Extract codelists from JSON files
a05_ExtractCodelistFromJSONfile.RmdExtracting codelists from JSON files
In this vignette, we will explore the functions that help us to generate codelists from JSON files. There are two main types of JSON files we can work with:
- Concept sets: These files usually contain a set of concepts that are grouped together based on a common definition or a clinical meaning. Each concept set may include inclusion/exclusion rules, descendants, and mapping criteria to define the exact scope of concepts included.
- Cohorts: These files define cohorts, which are groups of individuals meeting specific criteria for inclusion in a study. The cohort definitions also include embedded concept sets, logic criteria, time windows, and other metadata needed for cohort construction.
In the following sections, we will explore how to use specific functions to extract the codelists generated by these two type of JSON files. Specifically, we will delve into:
-
codesFromConceptSet(): to extract concept IDs directly from a concept set JSON. -
codesFromCohort(): to extract concept IDs from the concept sets embedded within a cohort definition JSON.
Hence, we will start by loading the necessary packages, creating a mock cdm, and saving the mock json files we are going to use to reproduce the example.
# Loading necessary files
library(omopgenerics)
library(CodelistGenerator)
library(dplyr)
library(jsonlite)
# Creating mock cdm
cdm <- mockVocabRef()
# Reading mock json files
arthritis_desc <- fromJSON(system.file("concepts_for_mock/arthritis_desc.json", package = "CodelistGenerator")) |> toJSON(pretty = TRUE, auto_unbox = TRUE)
arthritis_no_desc <- fromJSON(system.file("concepts_for_mock/arthritis_no_desc.json", package = "CodelistGenerator")) |> toJSON(pretty = TRUE, auto_unbox = TRUE)
arthritis_with_excluded <- fromJSON(system.file("concepts_for_mock/arthritis_with_excluded.json", package = "CodelistGenerator")) |> toJSON(pretty = TRUE, auto_unbox = TRUE)
arthritis_desc_cohort <- fromJSON(system.file("cohorts_for_mock/oa_desc.json", package = "CodelistGenerator")) |> toJSON(pretty = TRUE, auto_unbox = TRUE)Bear in mind that the structure of the vocabulary in our mock cdm is
the following 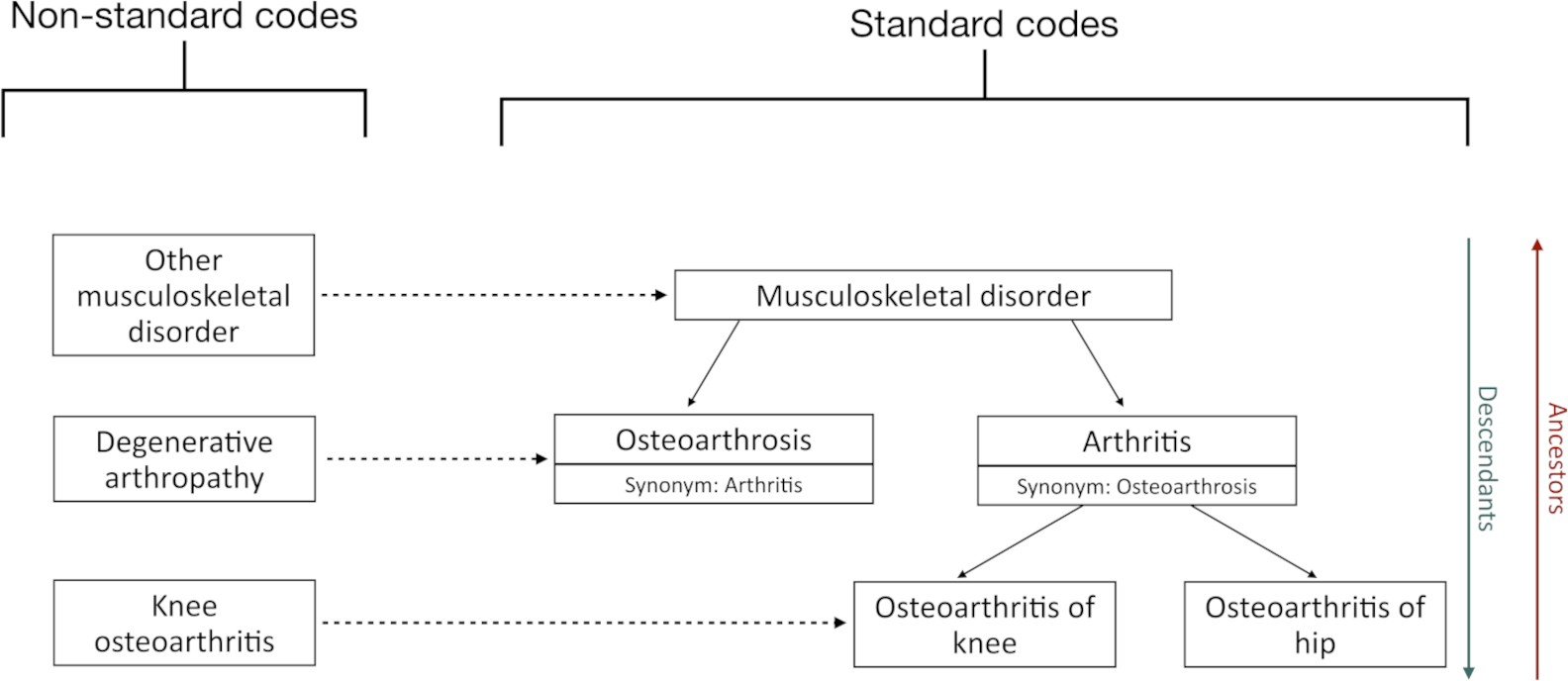
Codes from concept sets JSON files
Now, we are going to extract the concept ids provided a concept set JSON file
concepts <- codesFromConceptSet(cdm,
path = system.file(package = "CodelistGenerator","concepts_for_mock"),
type = "codelist_with_details")Notice that we have used the argument type to define the
output as codelist_with_details, but we could also obtain a
simple codelist. Let’s have a look at the codelist we have
just upload, which contain a set of concept ids to define
arthritis:
concepts
#>
#> ── 3 codelists with details ────────────────────────────────────────────────────
#>
#> - arthritis_desc (3 codes)
#> - arthritis_no_desc (1 codes)
#> - arthritis_with_excluded (2 codes)Include descendants
Let’s have a look at the first json file, named “arthritis_desc”
arthritis_desc
#> {
#> "items": [
#> {
#> "concept": {
#> "CONCEPT_ID": 3
#> },
#> "isExcluded": false,
#> "includeDescendants": true,
#> "includeMapped": false
#> }
#> ]
#> }Notice that in this codelist, we have concept_id=3 and
includeDescendants=TRUE, so the final codelist we have
obtained using codesFromConceptSet() is
concepts$arthritis_desc
#> # A tibble: 3 × 5
#> concept_id concept_name domain_id vocabulary_id standard_concept
#> <int> <chr> <chr> <chr> <chr>
#> 1 3 Arthritis Condition SNOMED standard
#> 2 5 Osteoarthritis of hip Condition SNOMED standard
#> 3 4 Osteoarthritis of knee Condition SNOMED standardNote that cdm is one of the arguments because it is used
to get the descendants (if needed) the result can vary cdm
to cdm if different vocabulary versions are used.
Exclude descendants
If descendants are set to exclude in the json file, the function will not provide the descendants:
arthritis_no_desc
#> {
#> "items": [
#> {
#> "concept": {
#> "CONCEPT_ID": 3
#> },
#> "isExcluded": false,
#> "includeDescendants": false,
#> "includeMapped": false
#> }
#> ]
#> }
concepts$arthritis_no_desc
#> # A tibble: 1 × 5
#> concept_id concept_name domain_id vocabulary_id standard_concept
#> <int> <chr> <chr> <chr> <chr>
#> 1 3 Arthritis Condition SNOMED standardExclude concepts
It can be that the json file specifies concepts that must be
excluded. This will also be taken into account when creating the final
codelist using codesFromConceptSet():
arthritis_with_excluded
#> {
#> "items": [
#> {
#> "concept": {
#> "CONCEPT_ID": 3
#> },
#> "isExcluded": false,
#> "includeDescendants": true,
#> "includeMapped": false
#> },
#> {
#> "concept": {
#> "CONCEPT_ID": 4
#> },
#> "isExcluded": true,
#> "includeDescendants": false,
#> "includeMapped": false
#> }
#> ]
#> }
concepts$arthritis_with_excluded
#> # A tibble: 2 × 5
#> concept_id concept_name domain_id vocabulary_id standard_concept
#> <int> <chr> <chr> <chr> <chr>
#> 1 3 Arthritis Condition SNOMED standard
#> 2 5 Osteoarthritis of hip Condition SNOMED standardCodes from cohort JSON files
Now, we are going to extract the concept ids provided a cohort JSON file. To do that, we just need to provide the path where we saved the json files:
concepts <- codesFromCohort(cdm,
path = system.file(package = "CodelistGenerator","cohorts_for_mock"),
type = "codelist_with_details")
concepts <- newCodelistWithDetails(list("arthritis" = concepts$arthritis))Let’s have a look at the codelist we have just upload:
arthritis_desc_cohort
#> {
#> "ConceptSets": [
#> {
#> "id": 0,
#> "name": "arthritis",
#> "expression": {
#> "items": [
#> {
#> "concept": {
#> "CONCEPT_CLASS_ID": "Clinical Finding",
#> "CONCEPT_CODE": "396275006",
#> "CONCEPT_ID": 3,
#> "CONCEPT_NAME": "Arthritis",
#> "DOMAIN_ID": "Condition",
#> "INVALID_REASON": "V",
#> "INVALID_REASON_CAPTION": "Valid",
#> "STANDARD_CONCEPT": "S",
#> "STANDARD_CONCEPT_CAPTION": "Standard",
#> "VOCABULARY_ID": "SNOMED"
#> },
#> "includeDescendants": true
#> }
#> ]
#> }
#> },
#> {
#> "id": 1,
#> "name": "Other",
#> "expression": {
#> "items": [
#> {
#> "concept": {
#> "CONCEPT_CLASS_ID": "Clinical Finding",
#> "CONCEPT_CODE": "422504002",
#> "CONCEPT_ID": 5,
#> "CONCEPT_NAME": "Osteoarthritis of hip",
#> "DOMAIN_ID": "Condition",
#> "INVALID_REASON": "V",
#> "INVALID_REASON_CAPTION": "Valid",
#> "STANDARD_CONCEPT": "S",
#> "STANDARD_CONCEPT_CAPTION": "Standard",
#> "VOCABULARY_ID": "SNOMED"
#> }
#> }
#> ]
#> }
#> }
#> ],
#> "PrimaryCriteria": {
#> "CriteriaList": [
#> {
#> "ConditionOccurrence": {
#> "CodesetId": 0
#> },
#> "Observation": {}
#> },
#> {
#> "ConditionOccurrence": {},
#> "Observation": {
#> "CodesetId": 0
#> }
#> },
#> {
#> "ConditionOccurrence": {
#> "CodesetId": 1
#> },
#> "Observation": {}
#> }
#> ],
#> "ObservationWindow": {
#> "PriorDays": 0,
#> "PostDays": 0
#> },
#> "PrimaryCriteriaLimit": {
#> "Type": "First"
#> }
#> },
#> "QualifiedLimit": {
#> "Type": "First"
#> },
#> "ExpressionLimit": {
#> "Type": "First"
#> },
#> "InclusionRules": [],
#> "CensoringCriteria": [],
#> "CollapseSettings": {
#> "CollapseType": "ERA",
#> "EraPad": 0
#> },
#> "CensorWindow": {},
#> "cdmVersionRange": ">=5.0.0"
#> }
concepts$arthritis
#> # A tibble: 3 × 5
#> concept_id concept_name domain_id vocabulary_id standard_concept
#> <int> <chr> <chr> <chr> <chr>
#> 1 3 Arthritis Condition SNOMED standard
#> 2 5 Osteoarthritis of hip Condition SNOMED standard
#> 3 4 Osteoarthritis of knee Condition SNOMED standard