Identify and summarise indications among a drug cohort
Source:vignettes/indication.Rmd
indication.RmdIntroduction
In this vignette, we demonstrate the functionality provided by the DrugUtilisation package to help understand the indications of patients in a drug cohort.
The DrugUtilisation package is designed to work with data in the OMOP CDM format, so our first step is to create a reference to the data using the DBI and CDMConnector packages.
library(DrugUtilisation)
library(omock)
library(CDMConnector)
library(dplyr)
library(PatientProfiles)
cdm <- mockCdmFromDataset(datasetName = "GiBleed", source = "duckdb")Create a drug utilisation cohort
We will use acetaminophen as our example drug. We’ll start by creating a cohort of acetaminophen users. Here we’ll include all acetaminophen records using a gap era of 7 days, but as we’ve seen in the previous vignette we could have also applied various other inclusion criteria.
cdm <- generateIngredientCohortSet(
cdm = cdm,
name = "acetaminophen_users",
ingredient = "acetaminophen",
gapEra = 7
)Note that addIndication works with a cohort as input, in
this example we will use drug cohorts created with
generateDrugUtilisationCohortSet but the input cohorts can
be generated using many other ways.
Create a indication cohort
Next we will create a set of indication cohorts. In this case we will
create cohorts for sinusitis and bronchitis using
CDMConnector::generateConceptCohortSet().
indications <- list(
sinusitis = c(257012, 4294548, 40481087),
bronchitis = c(260139, 258780)
)
cdm <- generateConceptCohortSet(
cdm = cdm, name = "indications_cohort", indications, end = 0
)
cdmAdd indications with addIndication() function
Now that we have these two cohort tables, one with our drug cohort and another with our indications cohort, we can assess patient indications. For this we will specify a time window around the drug cohort start date for which we identify any intersection with the indication cohort. We can add this information as a new variable on our cohort table. This function will add a new column per window provided with the label of the indication.
cdm[["acetaminophen_users"]] <- cdm[["acetaminophen_users"]] |>
addIndication(
indicationCohortName = "indications_cohort",
indicationWindow = list(c(-30, 0)),
indexDate = "cohort_start_date"
)
cdm[["acetaminophen_users"]] |>
glimpse()
#> Rows: ??
#> Columns: 5
#> Database: DuckDB 1.4.4 [unknown@Linux 6.14.0-1017-azure:R 4.5.2//tmp/Rtmpt9KhGV/file21414dbf1319.duckdb]
#> $ cohort_definition_id <int> 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1…
#> $ subject_id <int> 152, 363, 439, 826, 856, 925, 1025, 1072, 1144, 1…
#> $ cohort_start_date <date> 2017-02-26, 2005-07-01, 1987-08-17, 1993-03-16, …
#> $ cohort_end_date <date> 2017-03-19, 2005-07-01, 1987-08-24, 1993-03-30, …
#> $ indication_m30_to_0 <chr> "none", "none", "none", "bronchitis", "none", "br…We can see that individuals are classified as having sinusistis (without bronchitis), bronchitis (without sinusitis), sinusitis and bronchitis, or no observed indication.
cdm[["acetaminophen_users"]] |>
group_by(indication_m30_to_0) |>
tally()
#> # Source: SQL [?? x 2]
#> # Database: DuckDB 1.4.4 [unknown@Linux 6.14.0-1017-azure:R 4.5.2//tmp/Rtmpt9KhGV/file21414dbf1319.duckdb]
#> indication_m30_to_0 n
#> <chr> <dbl>
#> 1 none 11351
#> 2 bronchitis and sinusitis 3
#> 3 bronchitis 2527
#> 4 sinusitis 18As well as the indication cohort table, we can also use the clinical tables in the OMOP CDM to identify other, unknown, indications. Here we consider anyone who is not in an indication cohort but has a record in the condition occurrence table to have an “unknown” indication. We can see that many of the people previously considered to have no indication are now considered as having an unknown indication as they have a condition occurrence record in the 30 days up to their drug initiation.
cdm[["acetaminophen_users"]] |>
select(!"indication_m30_to_0") |>
addIndication(
indicationCohortName = "indications_cohort",
indicationWindow = list(c(-30, 0)),
unknownIndicationTable = "condition_occurrence"
) |>
group_by(indication_m30_to_0) |>
tally()
#> # Source: SQL [?? x 2]
#> # Database: DuckDB 1.4.4 [unknown@Linux 6.14.0-1017-azure:R 4.5.2//tmp/Rtmpt9KhGV/file21414dbf1319.duckdb]
#> indication_m30_to_0 n
#> <chr> <dbl>
#> 1 bronchitis 2527
#> 2 sinusitis 18
#> 3 bronchitis and sinusitis 3
#> 4 none 7
#> 5 unknown 11344We can add indications for multiple time windows. Unsurprisingly we find more potential indications for wider windows (although this will likely increase our risk of false positives).
cdm[["acetaminophen_users"]] <- cdm[["acetaminophen_users"]] |>
select(!"indication_m30_to_0") |>
addIndication(
indicationCohortName = "indications_cohort",
indicationWindow = list(c(0, 0), c(-30, 0), c(-365, 0)),
unknownIndicationTable = "condition_occurrence"
)
cdm[["acetaminophen_users"]] |>
group_by(indication_0_to_0) |>
tally()
#> # Source: SQL [?? x 2]
#> # Database: DuckDB 1.4.4 [unknown@Linux 6.14.0-1017-azure:R 4.5.2//tmp/Rtmpt9KhGV/file21414dbf1319.duckdb]
#> indication_0_to_0 n
#> <chr> <dbl>
#> 1 bronchitis 2524
#> 2 unknown 11211
#> 3 none 163
#> 4 sinusitis 1
cdm[["acetaminophen_users"]] |>
group_by(indication_m30_to_0) |>
tally()
#> # Source: SQL [?? x 2]
#> # Database: DuckDB 1.4.4 [unknown@Linux 6.14.0-1017-azure:R 4.5.2//tmp/Rtmpt9KhGV/file21414dbf1319.duckdb]
#> indication_m30_to_0 n
#> <chr> <dbl>
#> 1 unknown 11344
#> 2 bronchitis 2527
#> 3 sinusitis 18
#> 4 bronchitis and sinusitis 3
#> 5 none 7
cdm[["acetaminophen_users"]] |>
group_by(indication_m365_to_0) |>
tally()
#> # Source: SQL [?? x 2]
#> # Database: DuckDB 1.4.4 [unknown@Linux 6.14.0-1017-azure:R 4.5.2//tmp/Rtmpt9KhGV/file21414dbf1319.duckdb]
#> indication_m365_to_0 n
#> <chr> <dbl>
#> 1 bronchitis 2615
#> 2 sinusitis 211
#> 3 bronchitis and sinusitis 101
#> 4 none 4
#> 5 unknown 10968Summarise indications with summariseIndication()
Instead of adding variables with indications like above, we could
instead obtain a general summary of observed indications.
summariseIndication has similar arguments to
addIndication(), but returns a summary result of the
indication.
indicationSummary <- cdm[["acetaminophen_users"]] |>
select(!starts_with("indication")) |>
summariseIndication(
indicationCohortName = "indications_cohort",
indicationWindow = list(c(0, 0), c(-30, 0), c(-365, 0)),
unknownIndicationTable = c("condition_occurrence")
)We can then easily create a plot or a table of the results
tableIndication(indicationSummary)|
CDM name
|
||
|---|---|---|
|
GiBleed
|
||
| Indication | Estimate name |
Cohort name
|
| acetaminophen | ||
| Indication on index date | ||
| bronchitis | N (%) | 2,524 (18.16 %) |
| sinusitis | N (%) | 1 (0.01 %) |
| bronchitis and sinusitis | N (%) | 0 (0.00 %) |
| unknown | N (%) | 11,211 (80.66 %) |
| none | N (%) | 163 (1.17 %) |
| not in observation | N (%) | 0 (0.00 %) |
| Indication from 30 days before to the index date | ||
| bronchitis | N (%) | 2,527 (18.18 %) |
| sinusitis | N (%) | 18 (0.13 %) |
| bronchitis and sinusitis | N (%) | 3 (0.02 %) |
| unknown | N (%) | 11,344 (81.62 %) |
| none | N (%) | 7 (0.05 %) |
| not in observation | N (%) | 0 (0.00 %) |
| Indication from 365 days before to the index date | ||
| bronchitis | N (%) | 2,615 (18.81 %) |
| sinusitis | N (%) | 211 (1.52 %) |
| bronchitis and sinusitis | N (%) | 101 (0.73 %) |
| unknown | N (%) | 10,968 (78.91 %) |
| none | N (%) | 4 (0.03 %) |
| not in observation | N (%) | 0 (0.00 %) |
plotIndication(indicationSummary)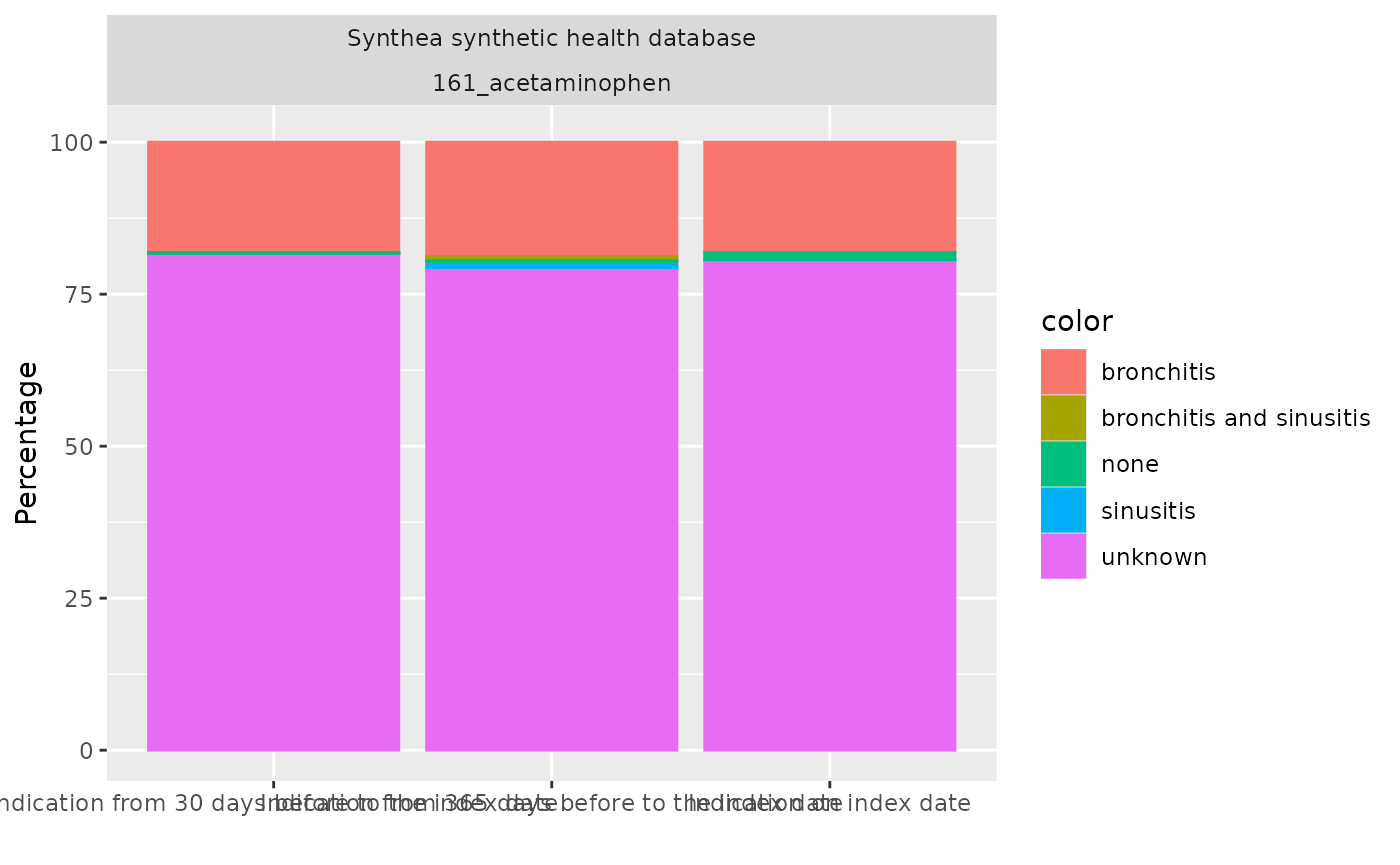
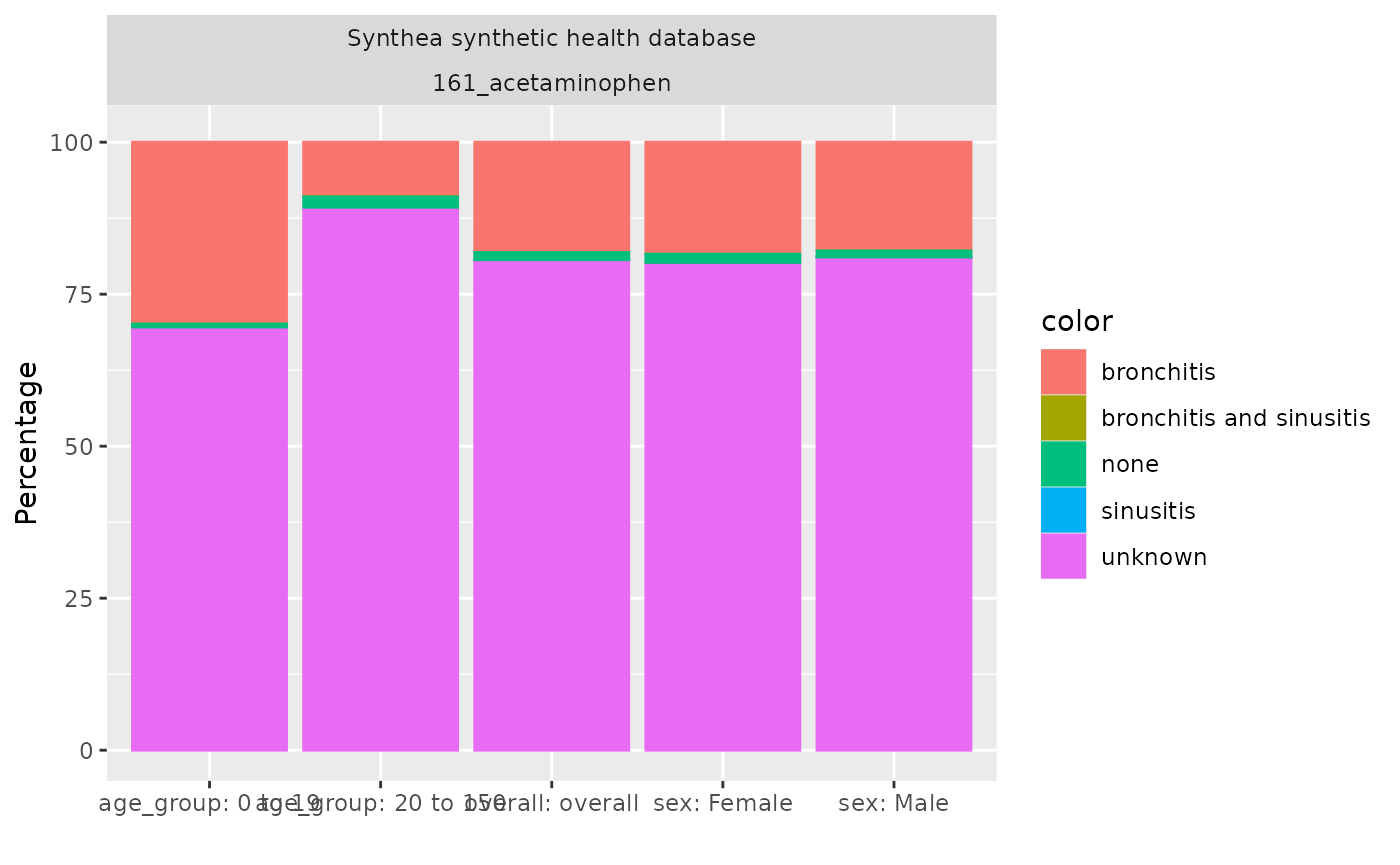
As well as getting these overall results, we can also stratify the results by some variables of interest. For example, here we stratify our results by age groups and sex.
indicationSummaryStratified <- cdm[["acetaminophen_users"]] |>
select(!starts_with("indication")) |>
addDemographics(ageGroup = list(c(0, 19), c(20, 150))) |>
summariseIndication(
strata = list("age_group", "sex"),
indicationCohortName = "indications_cohort",
indicationWindow = list(c(0, 0), c(-30, 0), c(-365, 0)),
unknownIndicationTable = c("condition_occurrence")
)
tableIndication(indicationSummaryStratified)|
CDM name
|
||||||
|---|---|---|---|---|---|---|
|
GiBleed
|
||||||
|
Cohort name
|
||||||
|
acetaminophen
|
||||||
|
Age group
|
||||||
|
overall
|
0 to 19
|
20 to 150
|
overall
|
|||
| Indication | Estimate name |
Sex
|
||||
| overall | overall | overall | Female | Male | ||
| Indication on index date | ||||||
| bronchitis | N (%) | 2,524 (18.16 %) | 1,823 (29.90 %) | 701 (8.98 %) | 1,290 (18.42 %) | 1,234 (17.90 %) |
| sinusitis | N (%) | 1 (0.01 %) | 1 (0.02 %) | 0 (0.00 %) | 0 (0.00 %) | 1 (0.01 %) |
| bronchitis and sinusitis | N (%) | 0 (0.00 %) | 0 (0.00 %) | 0 (0.00 %) | 0 (0.00 %) | 0 (0.00 %) |
| unknown | N (%) | 11,211 (80.66 %) | 4,242 (69.59 %) | 6,969 (89.31 %) | 5,619 (80.23 %) | 5,592 (81.10 %) |
| none | N (%) | 163 (1.17 %) | 30 (0.49 %) | 133 (1.70 %) | 95 (1.36 %) | 68 (0.99 %) |
| not in observation | N (%) | 0 (0.00 %) | 0 (0.00 %) | 0 (0.00 %) | 0 (0.00 %) | 0 (0.00 %) |
| Indication from 30 days before to the index date | ||||||
| bronchitis | N (%) | 2,527 (18.18 %) | 1,826 (29.95 %) | 701 (8.98 %) | 1,291 (18.43 %) | 1,236 (17.93 %) |
| sinusitis | N (%) | 18 (0.13 %) | 15 (0.25 %) | 3 (0.04 %) | 11 (0.16 %) | 7 (0.10 %) |
| bronchitis and sinusitis | N (%) | 3 (0.02 %) | 2 (0.03 %) | 1 (0.01 %) | 1 (0.01 %) | 2 (0.03 %) |
| unknown | N (%) | 11,344 (81.62 %) | 4,253 (69.77 %) | 7,091 (90.88 %) | 5,701 (81.40 %) | 5,643 (81.84 %) |
| none | N (%) | 7 (0.05 %) | 0 (0.00 %) | 7 (0.09 %) | 0 (0.00 %) | 7 (0.10 %) |
| not in observation | N (%) | 0 (0.00 %) | 0 (0.00 %) | 0 (0.00 %) | 0 (0.00 %) | 0 (0.00 %) |
| Indication from 365 days before to the index date | ||||||
| bronchitis | N (%) | 2,615 (18.81 %) | 1,883 (30.89 %) | 732 (9.38 %) | 1,353 (19.32 %) | 1,262 (18.30 %) |
| sinusitis | N (%) | 211 (1.52 %) | 191 (3.13 %) | 20 (0.26 %) | 108 (1.54 %) | 103 (1.49 %) |
| bronchitis and sinusitis | N (%) | 101 (0.73 %) | 96 (1.57 %) | 5 (0.06 %) | 39 (0.56 %) | 62 (0.90 %) |
| unknown | N (%) | 10,968 (78.91 %) | 3,926 (64.40 %) | 7,042 (90.25 %) | 5,504 (78.58 %) | 5,464 (79.25 %) |
| none | N (%) | 4 (0.03 %) | 0 (0.00 %) | 4 (0.05 %) | 0 (0.00 %) | 4 (0.06 %) |
| not in observation | N (%) | 0 (0.00 %) | 0 (0.00 %) | 0 (0.00 %) | 0 (0.00 %) | 0 (0.00 %) |
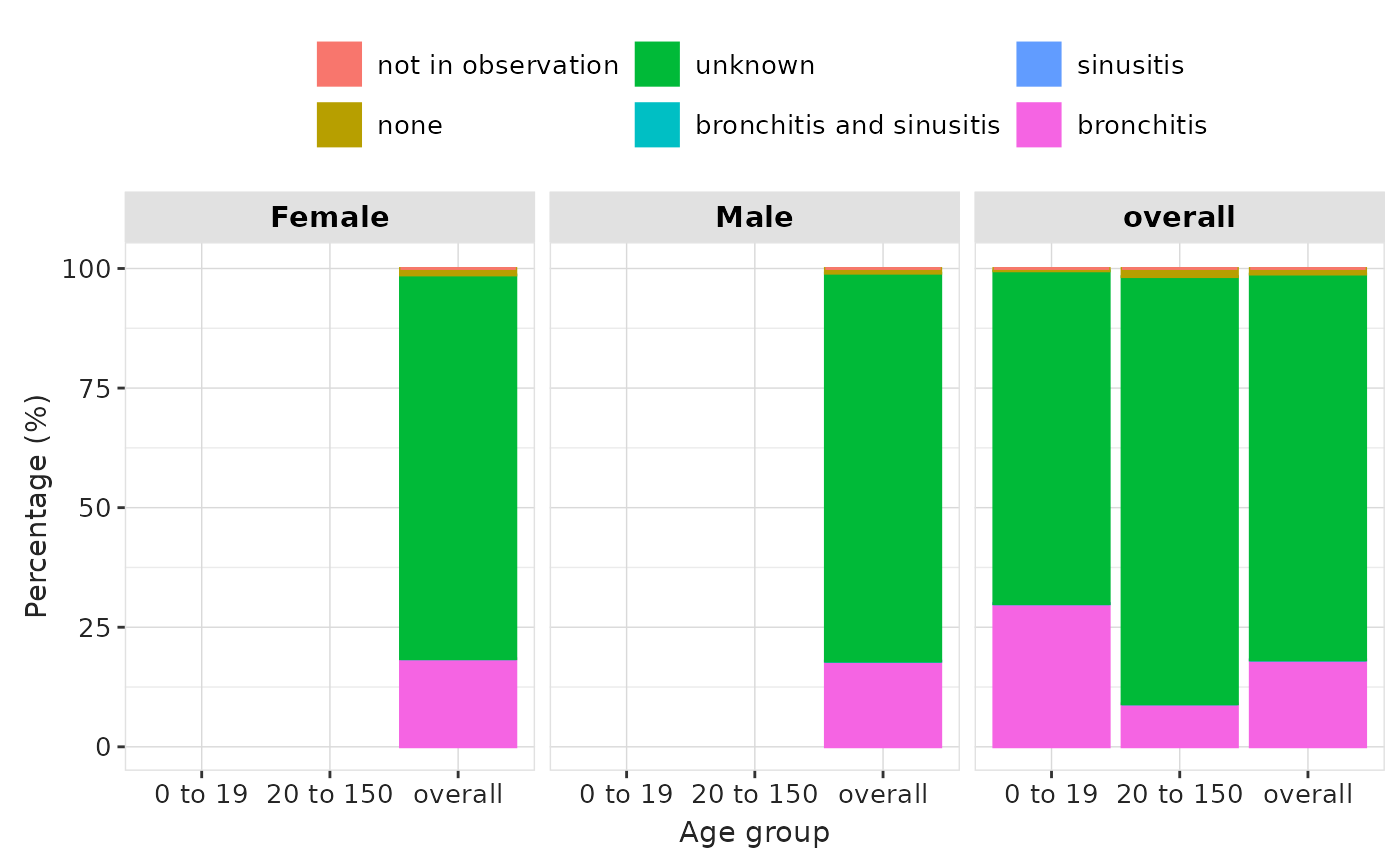
indicationSummaryStratified |>
filter(variable_name == "Indication on index date") |>
plotIndication(
facet = . ~ age_group + sex,
colour = "variable_level"
)
Custom plotting
Instead of having the indication on the x-axis, we can choose a different variable. For example we can have the age group on the x-axis and stratify our results by sex. Furthermore the plot can be a stacked bar plot and the x and y don’t need to be swapped as in the previous plot.
indicationSummaryStratified |>
filter(variable_name == "Indication on index date") |>
plotIndication(
facet = . ~ sex,
x = "age_group",
colour = "variable_level",
position = "stack"
)